내가 학습한 CS를 바탕으로 비동기가 더 적절하다고 가정하고 파일 업로드 기능을 구현했다. 그리고 파일 쓰기 작업을 비동기 처리하며 순차적으로 쓰고, 정확히 잘 써졌는지 확인하는 다른 작업들이 추가되었다. 이론적으론 비동기가 리소스를 많이 사용하더라도 결국 I/O 작업이 가장 오래 걸리기 때문에 동기 처리보다 빨라야 할 것이다. 그래서 두 방식을 직접 비교하는 테스트를 진행했다.
사실 테스트는 가장 마지막에 했지만, 정리하는 글이니까 순서상 먼저 정리하려고 한다. 그 과정에서 여러 문제를 만나고 나름 해결했지만 그건 뒤에서 다시 정리하고 여기선 단순히 비교한 결과를 정리한다.
테스트 환경
우선 사용한 t3 micro 인스턴스는 대역폭이 5Gbps라서 부하를 주었을 때 서버 처리 속도가 더 빨라서 정확한 비교가 힘들었다. 그래서 대역폭 37Gbps인 m7i.24xlarge 인스턴스를 사용하여 테스트를 진행했다. 아래가 amazon에서 사용한 인스턴스의 스펙이다.

가격이 비싸서 우아한 테크 캠프에서도 계속 사용하지 못하고 2시간 정도 테스트 용도로만 사용했다.
요청은 10개의 t3 micro 인스턴스에서 서버에 요청을 보낸다. 이때 각 서버는 초당 5개의 요청을 보내며 하나의 요청 당 100MB 파일 업로드를 진행했다. 서버 입장에선 초당 50명의 사용자가 100MB 파일을 업로드하는 요청을 처리하는 것이다.
부하 테스트는 Locust로 진행했다.
비동기 처리 결과
리눅스의 vmstat 명령어로 컨텍스트 스위칭, 인터럽트 횟수 등을 살펴보았다.
in은 인터럽트, cs는 컨텍스트 스위칭을 의미한다.
r이 높으면 CPU 부하가 높을 수 있음을 의미한다.(cpu 작업을 위해 대기하는 작업 횟수를 의미한다.)

동기 처리 결과

위의 두 사진을 보면 비동기로 처리했을 때가 r, in, cs 값이 전체적으로 높은 것을 볼 수 있다. 비동기 처리의 경우 별도의 스레드 풀을 사용하기 때문에 InputStream에서 읽기 작업을 하는 것과 S3에 쓰기 요청을 하는 I/O 작업이 동시에 발생한다. 그래서 인터럽트 횟수가 당연히 많을 것이고, 스레드를 더 많이 사용하니 컨텍스트 스위칭 횟수도 당연히 높을 것이다. 또한 InputStream을 처리하면서 파싱 과정에서 많은 연산들을 하는데, S3에 쓰기 작업을 하는 동안 Blocking 되지 않고 CPU 작업을 계속 하니 CPU 부하 또한 높은 게 당연하다.(AtmoicInteger로 연산하는 것도 있으니 CPU 부하가 더 심했을 것이다.) 여기까지는 예상대로 동작하니 처리 속도가 얼마나 차이 나는지만 보면 된다. 서버 리소스를 많이 사용하는데 처리량까지 낮다면 사실 비동기 작업을 사용할 필요가 없을 테니 말이다.
조금 더 자세히는 cpu 항목에 있는 us와 sy 값이다. us는 user, sy는 system을 의미하는데, us는 user mode에서 실행중인 프로세스의 cpu 사용률(%)을, sy는 system(커널)에서 사용 중인 프로세스의 cpu 사용률(%)을 의미한다. 즉, 이 둘을 합한 값이 너무 크다면 cpu 사용률이 높다고 볼 수 있다. 찾아보니 둘을 합한 값이 70~80 이상이면 부하가 심한 것으로 판단할 수 있고, 90 이상이면 과부하 상태로 판단할 수 있다고 한다. 스크린샷 찍을 때는 r값만 봤는데, 이 부분을 자세히 보지 않은 것이 조금 아쉽다. 여튼 비동기 결과와 동기 결과를 비교해보면 us+sy 값은 비동기 처리에서 더 높음을 볼 수 있다. 결국 cpu로 처리할 작업이 많으니 r 값과 us+sy 값이 상대적으로 높을 수 밖에 없다.
동기, 비동기 처리량 비교

위 결과는 비동기로 처리했을 때의 결과로, RPS가 1.4인 것을 확인할 수 있다.
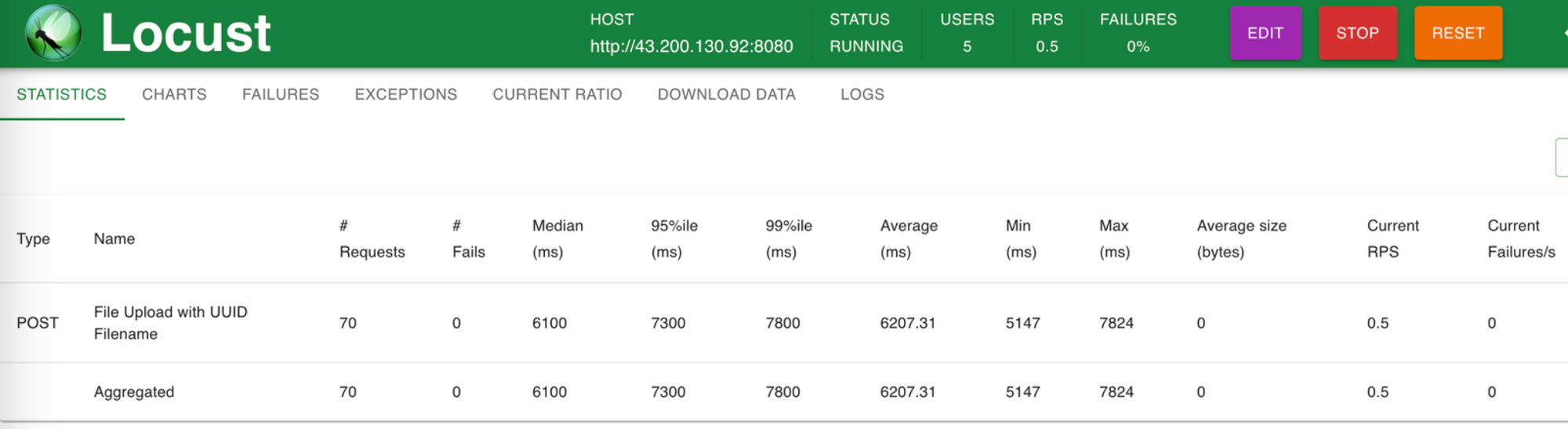
위 결과는 동기로 처리했을 때의 결과로, RPS가 0.5인 것을 확인할 수 있다.
결과적으로 비동기 처리가 훨씬 빨랐다. 내 예상보다 처리 속도가 차이가 많이 났는데, 아마 비동기 처리는 S3에 파일이 완전히 써지기 전에 사용자에게 요청에 대한 응답이 가기 때문일 것으로 생각된다. 즉, 쓰기 요청을 하고 그에 대한 응답은 받지 않고 리턴하니 빠른 것이다.
이거 테스트 하면서 대역폭 문제로 부하 테스트를 제대로 못했는데 그때 찍은 사진이 없어서 아쉽다. 정신없어서 스크린샷을 못 찍었는데 대역폭은 ifconfig 명령어로 모니터링했다. 아마 이거 관련한 내용을 나중에 따로 글로 정리할 것 같다.
OOM 문제
위의 과정에서 빼먹은 것이 있는데 OOM 문제이다. 사실 저기까지 가는동안 터진 문제 중 하나인데 간단해서 함께 정리하려고 한다.
제공받은 서버는 t3 micro이기 때문에 메모리가 1GB이다. 여기서 부하를 주고 테스트를 하니 아래와 같이 보기 좋게 OOM이 발생했다.

그래서 우선 아래와 같이 heap dump를 했다!

대부분 사용자 데이터를 처리하는 byte[] 버퍼가 메모리를 차지했다. 현재 5MB 단위로 끊어서 읽고, 스레드 풀에 복사해서 쓰기 작업을 하니 하나의 part를 처리하는데 10MB는 사용한다는 의미이다. 여하튼 해당 버퍼가 약 600MB 정도 사용하는 것을 볼 수 있다. 그리고 사진에는 없지만 DTO 같은 자바 객체가 약 200MB 사용하고 있었다. 벌써 800MB를 사용하고, 서버의 운영체제가 약 200MB 사용하니 당연히 OOM이 발생할 수밖에 없었다.
추가
뒤늦게 알았는데, 계산에 오류가 조금 있었다. 버퍼가 힙에는 약 400MB를 보유하고 있고, 이걸 참조하는 것 전체가 600MB 정도 된다. 그래서 실제 힙 영역 전체는 500MB 정도 할당이 된 것으로 보인다. 이것도 찾아보니 힙 메모리 설정을 따로 안했기 때문에, 물리 메모리의 절반으로 설정이 된 것으로 보인다. 그래서 운영체제가 200~300MB 사용하고 자바 프로세스가 약 500MB 사용하는 형태이다. 당시에는 1GB 메모리 자체가 너무 적어서 발생했던 것으로 생각했는데, 힙 영역이 약 500MB로 설정되고, 그 한도 내에서 작업을 처리하다가 OOM이 발생한 것이다. 그리고 우리 팀은 OOM이 발생하니 이 한도 내에서 문제 개선을 위해 노력했던 것이다.
해결 방법
해결 방법은 단순히 클라이언트 커넥션을 처리하는 스레드의 사용 개수와 S3 작업을 처리하는 스레드 풀의 스레드 개수를 조절하여 최대 가용한 메모리를 계산하는 것이었다.
어차피 5MB 단위로 S3에 쓰기 요청을 보내기 때문에 InputStream을 처리하는 스레드의 수 X 5MB를 한 값과 S3에 쓰기 요청을 하는 스레드의 수 X 5MB, 그리고 라인 단위로 boundary 체크를 위한 버퍼가 약 1MB를 차지한다. 이런 것들을 계산해서 톰캣 스레드 풀의 스레드 수, 파일 업로드 처리 스레드 풀의 스레드 수를 조절했다.
계산해보니 톰캣 스레드는 40, 파일 업로드 처리 스레드는 40, 스레드 풀의 대기 큐 사이즈는 10으로 설정했다. 그럼 40X5 + 40 X 5 + 10 X 5 = 450이 된다. 그리고 boundary 체크용 버퍼가 1MB이고 이건 톰캣 스레드가 가지고 가는 영역이니 40을 추가하면 약 500MB의 메모리를 사용하게 된다. 기타 자바 객체가 200MB 사용하고 OS 및 데몬 프로세스가 약 200MB 사용하니 이 정도가 가장 적당하다고 생각했다.
한 가지 아쉬운 게 있다면 t3 micro 환경이라는 점이었다. 내가 설정한 스레드들이 제대로 가용되지 않았다. 이건 또 대역폭 이슈여서 나중에 다시 정리해야겠다..
어쨌든 대역폭 이슈로 스레드 풀의 스레드가 제대로 가용되지 않았으면 저 스레드를 줄이고 톰캣 스레드를 늘리는 것도 하나의 방법이었을 것 같다. 당시에는 그렇게 했을 때 파일 업로드 요청이 많이 들어오면 대기 큐에서 Blocking 되는 작업들이 많아진다고 생각하여 이렇게 설정했는데, 대역폭 이슈로 내가 설정한 안전장치가 거의 사용되지 않을 줄은 상상도 못 했다.
후기
우선 조금 아쉬운 점은 테스트를 정확히 했는지 의문이다. 이런 가설을 세우고 테스트를 진행한 경험이 처음이라 뭔가 빼먹었을 수도 있다는 생각이 들었다. 이런 경험이 많은 사람이 있으면 조언을 구할 수 있을 것 같은데 아쉽다.
하지만 우아한 테크 캠프에서 인스턴스 지원을 해줘서 비싼 인스턴스로 부하 테스트도 해봐서 좋았다. 사실 혼자서 공부하면 t3 micro도 요금도 취준생 입장에서는 버거웠는데 이렇게 다양한 테스트를 할 수 있는 게 우테캠의 장점인 것 같다.(아쉽게도 싸피에서는 이 정도로 쓸 수는 없었다..). 그리고 이번에도 CS 공부한 게 많이 도움 되었다. CS 공부를 안 했다면 컨텍스트 스위칭이나 인터럽트 횟수 이런 건 찾아볼 생각도 안 했을 것 같다. 뭔가 발전한 느낌이었다.
'Java > My-Storage 프로젝트' 카테고리의 다른 글
| [My-Storage 개선하기] 로컬 환경에서 Docker로 Ceph 설치하기 (0) | 2025.01.04 |
|---|---|
| [My-Storage 개선하기] 데드락 해결, DB lock 사용 줄이기(2) - 테스트 (0) | 2024.12.19 |
| [My-Storage 개선하기] 데드락 해결, DB lock 사용 줄이기(1) (0) | 2024.12.19 |
| [우아한 테크 캠프 팀 프로젝트] 파일 이동 및 삭제 My-Storage(3) (0) | 2024.11.18 |
| [우아한 테크 캠프 팀 프로젝트] File Upload 구현하기. 효율적인 I/O처리를 위한 InputStream과 OutputStream의 분리 My-Storage(1) (1) | 2024.09.08 |