우아한 테크 캠프에서 3주 동안 진행하는 팀 프로젝트를 시작하게 되었다. 3주라는 짧은 시간 안에 아이디어를 내고 기능 구현도 하고 발표까지 해야 했다. 팀은 제비 뽑기로 결정했다. 제비 뽑기로 할 줄은 생각도 안 해서 나처럼 CS 공부가 중요하다고 생각하는 분과 팀을 하기로 했었고, 어떤 주제를 할지 미리 정했었다. 조작한 것처럼 제비 뽑기에서 그 분과 한 팀이 되었고 다른 팀원들에게 해당 주제와 대략적인 기능들을 설명해 주었는데 긍정적인 반응이라서 시작하게 되었다.
주제와 주제 선택 이유
주제는 네이버의 MyBOX, 구글의 Google Drive와 같은 클라우드 스토리지 서비스이다.
이 주제를 선택한 이유는 클라우드 스토리지도 일종의 파일 시스템이고, 그렇다면 CS를 많이 활용할 수 있지 않을까?라는 생각을 했기 때문이다. 그리고 구현할 기능들이 3주 안에 가능할 것 같이 느껴졌다. 구현할 기능은 파일 업로드 및 다운로드, 폴더와 파일 이동 및 삭제, 폴더와 파일 공유, 이미지 파일은 썸네일 제공 이렇게 크게 4가지였다.
페어 프로그래밍
위에서 말한 큰 기능을 6개의 milestone으로 나누었고, 각 기능마다 페어를 선정하여 페어 프로그래밍을 하기로 결정했다. 어쨌든 “테크 캠프”니까 1등을 한다는 마음가짐 보다는 많이 토론하고 얻어가기 위함이었다. 하나의 컴퓨터로 개발하다 보니 속도는 느렸지만, 작은 기능이라도 구현하며 어떤 방법이 좋은지, 어떤 문제가 발생할 수 있는지 등을 끊임없이 논의했다. 그리고 총 4명의 인원이 2개의 페어를 구성하여 진행했고, 각 페어끼리도 문제가 발생하면 함께 고민하고 해결법을 찾아갔다. 이렇게 진행하니 확실히 개개인의 역할을 나누고 진행했을 때보다 상대방이 구현한 기능도 대략 이해하고 있었다. 또한 내가 생각하지 못한 부분이나 다양한 시각에서 문제를 바라보고 해결하는 과정 자체가 도움이 많이 되었다.
우선 나는 파일 업로드, 폴더 및 파일 삭제, 폴더 및 파일 공유 기능을 페어 프로그래밍을 진행하며 담당하게 되었다. 여기선 파일 업로드 진행 과정을 기록하려고 한다.
MultipartResolver
Spring에는 멀티파트를 도와주는 녀석이 있다. 이걸 쓰면 간단하게 파일의 메타데이터와 파일의 InputStream으로 파일 데이터를 읽어올 수 있는데 문제가 하나 있다.

메모리나 디스크에 파일의 전체 데이터를 임시로 저장하고, 그 임시로 저장한 곳에서 새로 InputStream을 열어서 컨트롤러에서 처리할 수 있는 것이다. 이게 내가 사용하는 맥북이면 디스크 용량도 넉넉하니 그러려니 하겠지만 우아한 테크 캠프에서 사용한 EC2 인스턴스는 t3 micro이고 메모리는 1GB에 디스크는 30GB이다. 많은 사용자가 동시에 파일 업로드를 하게 된다면 디스크 용량마저 부족할 수 있을 것이고 메모리는 1GB라서 전부 디스크 I/O를 하게 될 테니 정말 느려질 것이다.
그래서 이럴바엔 그냥 직접 Stream을 직접 읽어서 처리하는 방법이 좋다고 생각했다.
멀티파트는 위와 같은 형식으로 요청 데이터를 보내기 때문에 boundary 기준으로만 잘 처리한다면 훨씬 효율적인 처리가 될 것이라고 생각했다. 그러기 위해선 다음과 같이 MultipartResolver 설정을 변경해줘야 했다.
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.web.multipart.MultipartResolver;
import org.springframework.web.multipart.support.StandardServletMultipartResolver;
@Configuration
public class MultipartConfiguration {
@Bean
public MultipartResolver multipartResolver() {
StandardServletMultipartResolver standardServletMultipartResolver = new StandardServletMultipartResolver();
standardServletMultipartResolver.setResolveLazily(true);
return standardServletMultipartResolver;
}
}setRsolveLazily 메서드를 따라가면 resolveLazily 값을 설정하는 것을 볼 수 있는데 이게 기본값이 false이다. false인 경우 스프링은 MultipartResolver로 멀티파트 요청을 자동으로 처리하여 임시저장을 하게 된다.
그래서 이 값을 true로 하게 되면 멀티파트 요청을 즉시 처리하지 않고, 애플리케이션이 실제로 멀티파트 데이터에 접근할 때만 발생하게 된다. 그럼 클라이언트 요청 데이터를 임시 저장을 하지 않으니 HttpServletRequest에서 직접 처리할 수 있게 된다.
/**
* MultipartFile은 임시 저장을 해서 직접 request를 통해 multipart/form-data를 파싱했습니다.
* 파싱을 하고 S3에 이미지를 업로드합니다.
*/
@ResponseStatus(HttpStatus.CREATED)
@PostMapping
public void handleFileUpload(HttpServletRequest request) throws Exception {
String boundary = "--" + extractBoundary(request.getContentType());
String finalBoundary = boundary + "--";
try (InputStream inputStream = request.getInputStream()) {
UploadContext context = new UploadContext(boundary, finalBoundary, new HashMap<>(), false);
processMultipartData(inputStream, context);
}
}
/**
* 클라이언트 요청을 buffer 단위로 읽어서 processBuffer 메소드를 호출합니다.
* processBuffer 메소드에서 헤더 파싱을 하고 boundary 체크를 하여 각 파트를 구분합니다.
*/
private void processMultipartData(InputStream inputStream, UploadContext context) throws Exception {
byte[] buffer = new byte[bufferSize];
ByteArrayOutputStream lineBuffer = new ByteArrayOutputStream(lineBufferMaxSize);
ByteArrayOutputStream contentBuffer = new ByteArrayOutputStream(INITIAL_CAPACITY);
PartContext partContext = new PartContext();
UploadState state = new UploadState();
try {
int bytesRead;
while ((bytesRead = inputStream.read(buffer)) != -1) {
if (processBuffer(buffer, bytesRead, lineBuffer, contentBuffer, context, partContext, state)) {
break;
}
}
} catch (ClientAbortException e) {
log.error("[ClientAbortException] 입력 처리 중 예외 발생. ERROR MESSAGE = {}", e.getMessage());
if (context.getFileMetadata() == null) {
throw ErrorCode.INVALID_MULTIPART_FORM_DATA.baseException();
}
fileMetadataRepository.updateUploadStatusById(context.getFileMetadata().metadataId());
} catch (AmazonS3Exception e) {
log.error("[AmazonS3Exception] 입력 예외로 완성되지 않은 S3 파일 제거 중 예외 발생. ERROR MESSAGE = {}", e.getMessage());
} catch (CustomException e) {
throw e;
} catch (Exception e) {
log.error("[Exception] 예상치 못한 예외가 발생했습니다: {}, {}", e.getCause(), e.getMessage());
throw e;
}
}데이터를 처리하는 과정의 일부이다. 파싱 하는 코드는 너무 길고 복잡해서 아래 링크를 통해 보는 것을 추천한다. 이 글에서는 핵심적인 것만 정리하고자 한다. https://github.com/seungh1024/My-Storage/blob/main/src/main/java/com/woowacamp/storage/domain/file/controller/MultipartFileController.java
참고로 직접 파싱하는파싱 하는 과정은 매우 힘들었다.. HTTP 규칙 따라서 파싱 하는 것이 이렇게 힘들지 몰랐다.
여전히 I/O는 느리다
MultipartResolver의 단점을 파악하고 데이터 처리를 직접 했지만, 여전히 I/O 작업은 느리다는 문제가 있었다. 나는 이게 마음에 들지 않았고, InputStream 작업과 OutputStream 작업을 분리하고 파일 쓰기 작업만 순서를 보장해 주면 되지 않을까?라는 생각을 하게 되었다.
이 순서를 보장하는 방법은 여러 개의 스레드 풀을 두고, 이 스레드 풀의 스레드는 하나로 고정한다. 그리고 각 파일의 고유한 값에서 hash를 추출하고 hash에 해당하는 스레드 풀에 OutputStream 작업을 넘겨준다면 순차 보장이 될 것이라고 생각했다. 이렇게 한다면 어쨌든 큐에 들어간 작업은 하나의 스레드가 처리하니 순차적으로 처리할 것이고, 이런 큐를 여러 개 두고 병렬로 작업한다면 시간이 크게 오래 걸리지도 않는다고 생각했다.
하지만 위 방법에도 문제가 있었는데, 작업이 큐에 골고루 분산되지 않는다는 점이다. 그래서 다른 방법을 고민하던 때에 파일 저장을 S3에 하기로 결정했고, S3는 Multipart Upload라는 좋은 기능을 제공해 주었다.
S3 Multipart Upload
S3는 여러 파일 쓰기 작업을 지원하는데, 그 중 하나이다. 파일을 쪼개서 보낼 수 있고, 보낸 조각들은 S3에서 재조립을 할 수 있다. 즉, 큰 파일을 전송할 때 유리하다. 1GB의 아찔한 메모리를 가진 t3 micro에서는 이걸 반드시 사용해야 한다고 생각했다.
Multipart Upload는 총 세가지 파트로 나뉘는데, 첫째로 S3에 어떤 파일 이름에 대한 데이터를 보내겠다는 요청, 둘째로 파일을 5MB 이상의 Chunk로 나눈 조각들을 보내고, 셋째로 파일 Chunk를 모두 보냈으면 완료되었다는 Complete 요청을 보내야 한다. 그럼 S3는 내가 파일을 보내겠다고 설정한 이름으로 chunk들을 받고, complete 요청을 받으면 그 즉시 chunk들을 재조립하여 하나의 파일로 만들어준다. 이때 우리가 주의해야 할 점은 각 chunk에 part number라는 번호를 붙여서 보내는데, 이 part number의 숫자가 오름차순이 되도록 파일을 합쳐준다. 즉, 이 번호만 오름차순으로 잘 보내면 정상적인 파일을 쓸 수 있다.
S3가 이렇게 고마운 기능을 제공해준 덕에 스레드 풀을 여러 개 관리할 필요가 없어졌다. chunk의 번호만 정렬 순서대로 잘 맞춰서 보내주면 되니 여러 스레드가 동시에 chunk를 보내는 작업을 해도 파일은 일관된 상태를 유지할 수 있었다. 1,2,3으로 보내든 1,3,2로 보내든 2,3,1로 보내든 S3는 1,2,3으로 맞춰서 하나의 파일로 만들어준다는 말이다.
InputStream과 OutputStream의 분리
HttpServletRequest의 InputStream은 동기적으로 데이터를 계속 읽고, 해당 데이터가 5MB 이상이 되면 S3에 Multipart Upload 요청을 보냈다. 그래서 쓰기 요청을 하는 별도의 스레드 풀이 필요했다.
import static com.woowacamp.storage.global.constant.CommonConstant.*;
import java.io.ByteArrayInputStream;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.atomic.AtomicInteger;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.stereotype.Service;
import com.amazonaws.AmazonClientException;
import com.amazonaws.services.s3.AmazonS3;
import com.amazonaws.services.s3.model.CompleteMultipartUploadRequest;
import com.amazonaws.services.s3.model.InitiateMultipartUploadResult;
import com.amazonaws.services.s3.model.PartETag;
import com.amazonaws.services.s3.model.UploadPartRequest;
import com.amazonaws.services.s3.model.UploadPartResult;
import com.woowacamp.storage.domain.file.dto.PartContext;
import com.woowacamp.storage.domain.file.repository.FileMetadataRepository;
import com.woowacamp.storage.domain.file.util.CustomS3BlockingQueuePolicy;
import com.woowacamp.storage.global.error.ErrorCode;
import lombok.extern.slf4j.Slf4j;
@Service
@Slf4j
public class FileWriterThreadPool {
@Value("${cloud.aws.credentials.bucketName}")
private String BUCKET_NAME;
private final Map<String, Integer> maxPartCountMap;
private final Map<String, AtomicInteger> currentPartCountMap;
private final AmazonS3 amazonS3;
private final ThreadPoolExecutor executorService;
private final FileMetadataRepository fileMetadataRepository;
public final ArrayBlockingQueue<Runnable> workQueue = new ArrayBlockingQueue<>(FILE_WRITER_QUEUE_SIZE);
public FileWriterThreadPool(AmazonS3 amazonS3, FileMetadataRepository fileMetadataRepository) {
this.amazonS3 = amazonS3;
this.maxPartCountMap = new HashMap<>();
this.currentPartCountMap = new HashMap<>();
this.executorService = new ThreadPoolExecutor(
FILE_WRITER_CORE_POOL_SIZE,
FILE_WRITER_MAXIMUM_POOL_SIZE,
FILE_WRITER_KEEP_ALIVE_TIME,
TimeUnit.SECONDS,
workQueue,
new CustomS3BlockingQueuePolicy()
);
this.fileMetadataRepository = fileMetadataRepository;
}
public void produce(InitiateMultipartUploadResult initResponse, String currentFileName, int partNumber,
byte[] contentBuffer, int bufferLength, List<PartETag> partETags) {
if (!currentPartCountMap.containsKey(currentFileName)) {
log.info("[Error Occurred] 이미 중단된 작업입니다. partNumber: {} ", partNumber);
fileMetadataRepository.deleteByUuidFileName(currentFileName);
throw ErrorCode.FILE_UPLOAD_FAILED.baseException();
}
executorService.execute(() -> {
uploadPart(initResponse.getUploadId(), currentFileName, partNumber, contentBuffer, bufferLength, partETags);
AtomicInteger currentConsumeCount = currentPartCountMap.get(currentFileName);
if (currentConsumeCount != null) {
currentConsumeCount.incrementAndGet();
}
Integer maxConsumeCount = maxPartCountMap.get(currentFileName);
if (maxConsumeCount != null
&& currentConsumeCount.get() >= maxConsumeCount) {
completeFileUpload(initResponse.getUploadId(), currentFileName, partETags);
}
});
}
public void finishFileUpload(PartContext partContext) {
maxPartCountMap.put(partContext.getUploadFileName(), partContext.getPartCount());
}
private void uploadPart(String uploadId, String key, int partNumber, byte[] data, int length,
List<PartETag> partETags) {
UploadPartRequest uploadRequest = new UploadPartRequest()
.withBucketName(BUCKET_NAME)
.withKey(key)
.withUploadId(uploadId)
.withPartNumber(partNumber)
.withInputStream(new ByteArrayInputStream(data, 0, length))
.withPartSize(length);
UploadPartResult uploadResult;
try {
uploadResult = amazonS3.uploadPart(uploadRequest);
} catch (AmazonClientException e) {
log.error("partNumber: {}, part upload가 정상적으로 동작하지 않습니다.", partNumber);
currentPartCountMap.remove(key);
fileMetadataRepository.deleteByUuidFileName(key);
return;
}
partETags.add(uploadResult.getPartETag());
}
private void completeFileUpload(String uploadId, String currentFileName, List<PartETag> partETags) {
log.info("currentThread: {}, finish upload", Thread.currentThread().getId());
maxPartCountMap.remove(currentFileName);
currentPartCountMap.remove(currentFileName);
CompleteMultipartUploadRequest completeRequest = new CompleteMultipartUploadRequest(BUCKET_NAME,
currentFileName, uploadId, partETags);
try {
amazonS3.completeMultipartUpload(completeRequest);
} catch (AmazonClientException e) {
log.error("[Error Occurred] completeFileUpload가 정상적으로 동작하지 않습니다.");
fileMetadataRepository.updateUploadStatusByUuid(currentFileName);
}
}
public void initializePartCount(String fileName) {
currentPartCountMap.put(fileName, new AtomicInteger(0));
}
}코드를 보면 각 Chunk를 보내는 uploadPart와 모든 파일 데이터를 처리했다는 completeFileUplaod 메서드는 있는데 이전에 말한 어떤 파일을 보내겠다는 초기화 요청이 없다. 해당 요청은 컨트롤러에서 파일 데이터를 보냈다면 그때 S3에 초기화 요청을 보내게 했다.
uplaodPart 메소드를 보면 uploadId는 우리가 설정한 파일의 고유한 UUID 값이고, key는 S3 버킷 이름, partNumber는 Part의 순서, data는 파일의 byte 값, List<PArtETag> partEtags는 각 Part에 대한 고유번호를 모두 저장한 리스트인데, completeFileUpload 요청에서 함께 보내는 데 사용된다. 각 Part 업로드가 끝나면 그 결과를 UploadPartResult로 받을 수 있는데, 여기서 PartETag 값을 가져와서 저장해 준다.
public void produce(InitiateMultipartUploadResult initResponse, String currentFileName, int partNumber,
byte[] contentBuffer, int bufferLength, List<PartETag> partETags) {
if (!currentPartCountMap.containsKey(currentFileName)) {
log.info("[Error Occurred] 이미 중단된 작업입니다. partNumber: {} ", partNumber);
fileMetadataRepository.deleteByUuidFileName(currentFileName);
throw ErrorCode.FILE_UPLOAD_FAILED.baseException();
}
executorService.execute(() -> {
uploadPart(initResponse.getUploadId(), currentFileName, partNumber, contentBuffer, bufferLength, partETags);
AtomicInteger currentConsumeCount = currentPartCountMap.get(currentFileName);
if (currentConsumeCount != null) {
currentConsumeCount.incrementAndGet();
}
Integer maxConsumeCount = maxPartCountMap.get(currentFileName);
if (maxConsumeCount != null
&& currentConsumeCount.get() >= maxConsumeCount) {
completeFileUpload(initResponse.getUploadId(), currentFileName, partETags);
}
});
}쓰기 작업이 분리된 곳은 결국 이 메서드 때문이다. InputStream에서 처리한 byte 버퍼를 이 스레드 풀이 처리해 준다. 스레드 풀에 우선 작업을 넣기만 한다면, 알아서 처리를 해줄 것이고, 파일의 순서는 S3가 보장해 주니 partNumber만 잘 보내면 된다.
위 코드에 특이한 점이 있는데 currentPartCountMap에서 AtomicInteger를 가져오고, maxPartCountMap이라는 곳에서 Integer 값을 가져와서 이를 비교하고 그 값이 일치하는 경우에만 completeFileUpload를 요청한다. 이렇게 한 이유는 스레드 풀의 스레드는 멀티 스레드로 동작하고, 다양한 이유들로 컨텍스트 스위칭되며 요청한 순서대로 작업을 처리하는 것이 보장되지 않기 때문이다. 즉, 그냥 마지막 part 작업을 스레드 풀에 요청한 이후 completeFileUpload를 요청하면 해당 요청이 S3에 먼저 도달하여 처리될 수 있다. 그럼 S3는 모든 part를 받지 못했음에도 part들을 합쳐서 하나의 파일로 만들어주고, 온전하지 않은 파일이 완성되는 문제가 발생한다.
/**
* header를 읽은 후, file type이라면 S3에 part upload를 알려주는 initiate request 입니다.
*/
private InitiateMultipartUploadResult initializeFileUpload(String fileName, String contentType) {
fileWriterThreadPool.initializePartCount(fileName);
ObjectMetadata metadata = new ObjectMetadata();
metadata.setContentType(contentType);
InitiateMultipartUploadRequest initRequest = new InitiateMultipartUploadRequest(bucketName,
fileName).withObjectMetadata(metadata);
return amazonS3.initiateMultipartUpload(initRequest);
}위의 InputStream과 OutputStream의 각각의 part 처리 개수를 세기 위해 컨트롤러에서 파일 쓰기 요청이 들어온 경우 위와 같은 작업을 진행한다. initializePartCount를 호출하면 해당 fileName으로 초기 값이 0인 AtomicInteger 객체가 생성된다. 그리고 S3에 파일을 쓸 것이라고 initiateMultipartUpload 요청을 보낸다. 그리고 InputStream은 동기적으로 처리되기 때문에, 컨트롤러 자체에서 part 처리 개수를 세어주고 있다.(여기 코드에는 안 보이지만)
여하튼 이렇게 온전한 파일을 쓰기 위한 작업을 처리했다.
스레드 풀에서 더 이상 처리할 수 없는 경우
추가로 고민한 부분은 스레드 풀에 작업이 너무 많이 쌓이면 OOM이 반드시 발생하는 것이었고 그래서 스레드 풀의 스레드 수를 조절했다. 하지만 이미 스레드들이 전부 가용된 상황에서 계속 작업을 추가하면 문제가 발생했다. 그래서 더이상 처리할 수 없는 경우에는 InputStream을 무리해서 처리하지 않도록 Blocking 할 작업이 필요하다고 생각했다.
public FileWriterThreadPool(AmazonS3 amazonS3, FileMetadataRepository fileMetadataRepository) {
this.amazonS3 = amazonS3;
this.maxPartCountMap = new HashMap<>();
this.currentPartCountMap = new HashMap<>();
this.executorService = new ThreadPoolExecutor(
FILE_WRITER_CORE_POOL_SIZE,
FILE_WRITER_MAXIMUM_POOL_SIZE,
FILE_WRITER_KEEP_ALIVE_TIME,
TimeUnit.SECONDS,
workQueue,
new CustomS3BlockingQueuePolicy()
);
this.fileMetadataRepository = fileMetadataRepository;
}위 코드를 다시 보면 CustomS3BlockingQueuePolicy 라는 것이 보인다. 이게 작업을 대기하는 큐의 정책을 정의해서 추가한 것인데, 대기 큐에도 작업이 가득 차서 더 이상 작업을 추가할 수 없을 때 Blocking 하는 정책을 추가했다.
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.RejectedExecutionException;
import java.util.concurrent.RejectedExecutionHandler;
import java.util.concurrent.ThreadPoolExecutor;
import lombok.extern.slf4j.Slf4j;
@Slf4j
public class CustomS3BlockingQueuePolicy implements RejectedExecutionHandler {
@Override
public void rejectedExecution(Runnable runnable, ThreadPoolExecutor executor) {
BlockingQueue<Runnable> queue = executor.getQueue();
try {
// 큐에 공간이 생길 때까지 무기한 대기
queue.put(runnable);
} catch (InterruptedException e) {
// 인터럽트 발생 시 현재 스레드의 인터럽트 상태를 설정
Thread.currentThread().interrupt();
throw new RejectedExecutionException("Task interrupted while waiting for queue space", e);
}
}
}RejectedExecutionHandler를 구현했다. 해당 인터페이스의 rejectedExecution 메서드는 ThreadPoolExecutor에 의해 작업이 거부될 때 호출된다. 이때 BlockingQueue를 작업 대기 큐로 사용하고 있고, 해당 큐에 데이터를 넣는 작업은 공간이 생기기 전까진 Blocking 된다. 그래서 간단히 더 이상 처리하지 못하는 작업을 Blocking할 수 있었다. 당연히 이 작업을 요청한 스레드는 InputStream을 처리하며 파일 데이터를 읽어오는 스레드이기 때문에 Blocking되어 더이상 사용자 요청을 처리하지 않고 대기한다.
물론 부하가 많을 때 많은 스레드들이 Blocking 될 수 있지만, 적어도 에러가 발생해서 어떤 Part를 잃어버리는 것보단 좋다고 생각한다. 만약 중간에 어떤 파일 데이터가 손실되어 S3에 저장된다면, 사용자는 깨진 파일을 보게 될 것이기 때문이다.
이외에도 DB에 메타 데이터를 저장하고, 메타 데이터가 일치하는지 비교하고, 폴더 삭제 중에 파일 쓰기가 되지 않는 등의 작업들이 있지만 파일 업로드를 구현하며 핵심이라고 생각하는 부분만 정리했다. 아마 이런 부가 작업들은 어려운 작업은 아니라고 생각해서 그런 것 같다.
파일 업로드 처리 과정
아래는 파일 업로드 요청이 처리되는 과정을 그림으로 나타낸 것이다.
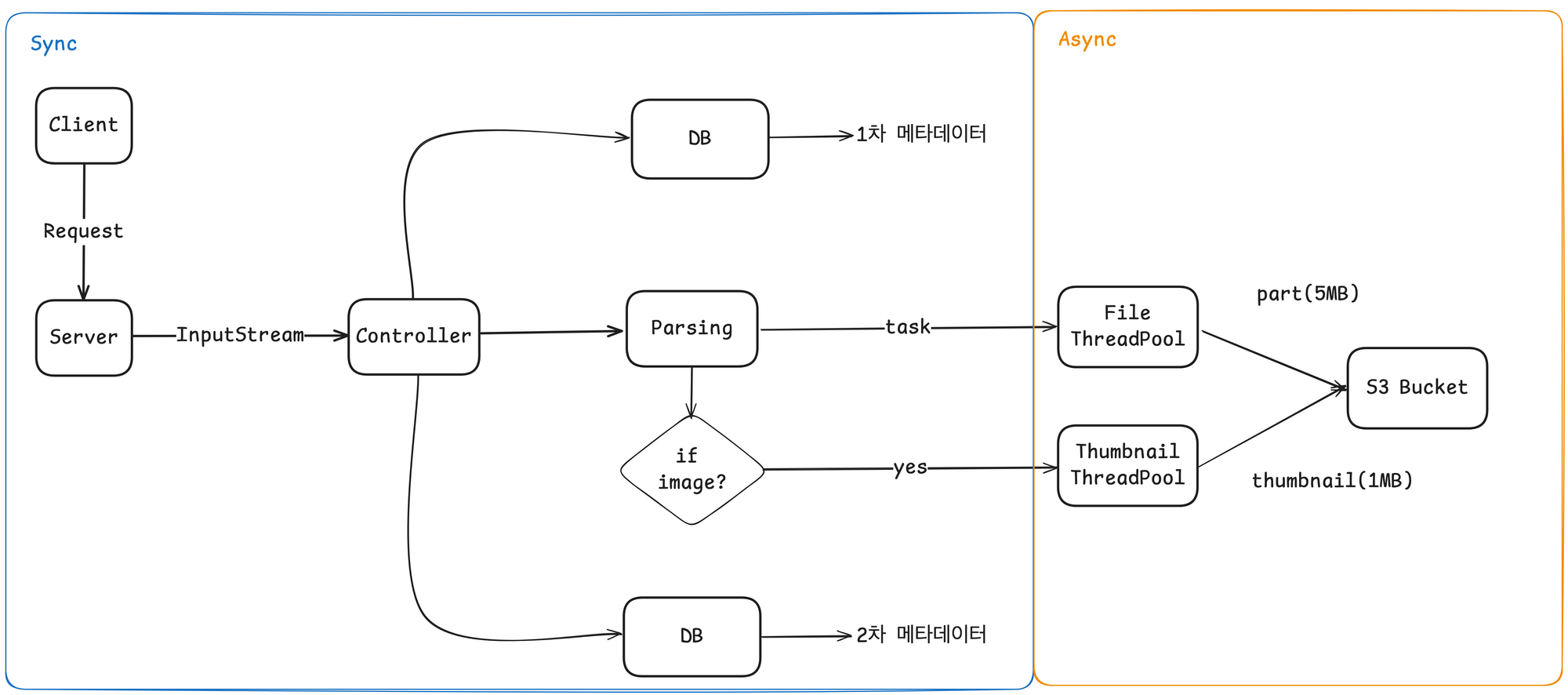
썸네일 기능도 파일 처리를 하며 동시에 처리하는데, 내가 담당한 기능은 아니기도 하고 가장 마지막에 추가한 기능이라 나중에 시간이 되면 짧게 정리해야겠다.
후기
정리는 간단하게 했지만 정말 고민을 많이 하며 진행했던 것 같다. 이전에 내가 이렇게까지 복잡하게 생각하고 구현한 적이 있나?라는 생각이 들 정도였다. 사실 예전에는 이렇게 생각을 못한 게 당연하다. 왜냐하면 그땐 CS를 공부하고 이해한 것이 아닌, 단순히 암기만 했기 때문이다. 그래서 어떤 문제가 발생할지, 문제가 있으면 어떻게 접근하고 해결할지 방법조차 몰랐던 것 같다.
첫 기능을 구현하면서도 CS가 굉장히 중요하다고 느꼈다. CS를 공부했기 때문에 I/O는 느리니까 분리해 보자는 생각도 하고, CAS이 적용된 AtomicInteger를 사용할 생각도 했던 것 같다. 그리고 확실히 리소스를 최대한 효율적으로 사용하려고 생각하고, 거기서 문제가 발생하지 않는지도 살펴보게 된 것 같다.
'Java > My-Storage 프로젝트' 카테고리의 다른 글
| [My-Storage 개선하기] 로컬 환경에서 Docker로 Ceph 설치하기 (0) | 2025.01.04 |
|---|---|
| [My-Storage 개선하기] 데드락 해결, DB lock 사용 줄이기(2) - 테스트 (0) | 2024.12.19 |
| [My-Storage 개선하기] 데드락 해결, DB lock 사용 줄이기(1) (0) | 2024.12.19 |
| [우아한 테크 캠프 팀 프로젝트] 파일 이동 및 삭제 My-Storage(3) (0) | 2024.11.18 |
| [우아한 테크 캠프 팀 프로젝트]동기 처리 vs 비동기 처리, 비동기 처리에서 발생한 OOM 문제 My-Storage(2) (0) | 2024.09.09 |