[My-Storage 개선하기] 데드락 해결, DB lock 사용 줄이기(2) - 테스트
테스트 환경 설정
DB, Redis, Spring 모두 별도의 환경에서 테스트를 하고자 했다. 개선 전의 서버와 비교를 하려면 동일한 환경을 보장하는 것이 중요하다고 생각했기 때문이다. 서버를 살 돈은 없었기에 로컬에서 도커를 사용해서 컨테이너 환경에서 cpu와 메모리를 제한했다.
Dockerfile
# 1. 빌드 단계: Gradle 이미지 사용
FROM gradle:7.6-jdk17 AS build
# 2. 작업 디렉토리 설정
WORKDIR /app
# 3. 필요한 파일 복사
COPY --chown=gradle:gradle . .
# 4. Gradle을 사용해 JAR 파일 빌드
RUN gradle clean build --no-daemon --stacktrace || (echo "Build failed. Check build logs for details." && tail -n 50 /app/build/reports/tests/test/index.html)
# 테스트 결과 복사
RUN cp -r build/docker /app/build || echo "No test reports available, build failed"
# 5. 실행 단계: 경량 JDK 이미지 사용
FROM openjdk:17-jdk-slim
# 6. 작업 디렉토리 설정
WORKDIR /app
# 7. 빌드한 JAR 파일 복사
COPY --from=build /app/build/libs/*.jar app.jar
# 8. 로그 디렉토리 만들기 및 권한 부여
RUN mkdir -p /app/logs && chmod -R 777 /app/logs
# 9. 애플리케이션 실행
ENTRYPOINT ["java", "-jar", "app.jar"]서버 이미지를 만들어 줄 도커 파일이다. gpt 도움을 받아 빠르게 작성했는데 세상 참 편리해진 것 같다.
도커 사용하면서 불편했던 점이 있는데, jar 파일을 빌드할 때 실패를 하면 어디서 실패했는지 build 디렉토리 아래 어딘가 index.html 파일로 알려주는데, 그 파일이 컨테이너 내부 환경에서 생성되고 빌드 실패로 컨테이너가 종료되니 어디서 문제가 생겼는지 찾기 힘들었다. 그래서 --stacktrace로 해당 파일의 일정 부분을 출력하도록 했다.
docker-compose.yml
version: '2.6'
services:
spring-server:
build:
context: .
dockerfile: Dockerfile
ports:
- "8080:8080"
environment:
- SPRING_PROFILES_ACTIVE=local
- SPRING_DATASOURCE_URL=jdbc:mysql://mysql:3306/test?connectTimeout=3000&socketTimeout=3000
- SPRING_DATASOURCE_USERNAME=root
- SPRING_DATASOURCE_PASSWORD=root
- SPRING_REDIS_URL=redis://redisson:6379
depends_on:
- mysql
- redisson
mem_limit: 1G
cpus: 2.0
volumes:
- ./logs/app.log:/app/logs/app.log
mysql:
image: mysql:8
environment:
MYSQL_ROOT_PASSWORD: root
MYSQL_DATABASE: test
ports:
- "8888:3306"
mem_limit: 1G
cpus: 2.0
redisson:
image: redis:7
ports:
- "9999:6379"
mem_limit: 512M
cpus: 1.0spring 서버와 mysql은 cpu 2 코어, 메모리 1G를 할당했고, 레디스의 경우 더 적게 할당했다. 왜냐하면 레디스는 부하가 크게 심하지 않았기 때문이다. 더 줄여도 문제는 없었다.
이때 cpus 값이 1.0, 2.0인 것은 논리적으로 1 코어, 2 코어만큼을 제한한다는 것이다. 정확히 특정 코어를 해당 컨테이너를 위해 제공하는 것이 아닌 논리적인 사용량이 2 코어만큼 사용할 수 있도록 제한한다는 것이다. 그리고 로그 파일을 보기 위해 volumes를 설정했다.
이게 찾아보니 코어 번호를 지정해서 제한도 가능한데, docker swarm을 사용하면 가능했다. 하지만 현재 클러스터를 구성하지는 않을 것이기 때문에 굳이 필요 없다고 생각했고 위와 같이 사용했다.

docker inspect 명령어를 사용하면 위와 같은 정보를 볼 수 있는데, 논리적인 할당을 했기 때문에 CpusetCpus에 아무 데이터가 없다. docker swarm을 사용하여 코어를 지정하면 해당 정보에 할당한 코어의 번호가 보인다고 한다.
톰캣 스레드 풀 설정도 했다.
최대 스레드 수는 200, 최대 커넥션 수는 200으로 설정했다. 그리고 대기 큐는 100으로 설정하고 connection-timeout은 5000ms로 설정했다.
기본 설정이 200인 것으로 아는데, 그냥 기본으로 한 것이다. 대기 큐의 경우는 크게 잡아야 할 필요를 못 느껴서 작게 설정했다. 어차피 현재 할당한 리소스로는 동시 사용자 수가 200명을 넘기기 힘들 것 같았기 때문이다.
시나리오 생각
- 루트 폴더만 존재하는 상태에서, 여러 사람들이 조회하고 추가하고 이동하는 상황을 가정한다.
- 이 경우 조회:생성:이동 = 6:2:2의 비율로 진행할 계획이다.
- 쓰기 작업이 많은 것 같지만 폴더를 공유해서 작업할 때는 쓰기 작업도 많을 것이라는 생각을 했기 때문이다.
- 이미 만들어진 폴더 구조에서 조회하고 이동하는 상황을 가정한다.
- 이 경우 조회:이동 = 7:3의 비율로 진행할 계획이다.
위 두 가지 시나리오를 생각했다. 삭제도 하면 좋지만, 폴더 트리가 크게 생성되기까지 더 오랜 시간이 걸리고, 충분히 크게 생성되지 않은 상태가 만들어질 수 있어서 제외했다. 무엇보다 현재 내가 테스트를 하려는 것은 락 사용을 없애고 분산락을 사용한 현재 서버가 얼마나 더 많은 요청을 처리할 수 있는지가 궁금했기 때문에 삭제가 아닌 락 사용이 많은 이동 작업만 해도 충분하다고 생각했다.
그리고 테스트를 편리하게 하기 위해 폴더 생성 시 항상 쓰기 권한으로 생성하도록 했다. 파일 이름도 여러 사람들이 동시에 작업하다 보면 겹칠 수 있기 때문에 이것도 고려해서 파일이 름의 경우 1~1000 정도의 정수 범위 내에서 랜덤 하게 숫자롤 뽑아서 생성하도록 했다. 생성된 폴더가 많을수록 겹치는 현상이 발생할 것이다.
참고로 부하 테스트는 locust를 이용했다. 아무래도 python이라서 코드 자체가 눈에 익숙하기 때문이다.
주의할 점
절대 로그를 콘솔에 찍지 않는 것을 추천한다. 별도의 서버면 상관없겠지만, 나처럼 로컬에서 한다면 콘솔에 로그를 찍는 행위가 컴퓨터를 죽일 수 있다. 컨테이너 실행과 종료를 편리하게 하기 위해 docker desktop을 사용 중인데, 해당 애플리케이션을 사용하면 콘솔에 찍히는 로그들을 볼 수 있다. 만약 부하를 주었을 때 수많은 로그가 찍히는 상황이라면, docker desktop에도 로그들이 찍히게 되고, 이러한 작업이 컴퓨터의 메모리를 굉장히 많이 써서 컴퓨터가 죽어버리는 현상이 발생했다.
error만 찍어서 문제가 없을 수도 있지만, 뭔가 설정상의 이슈로 모든 요청이 error만 찍어버린다면 문제가 생길 수 있다. 내가 그랬다..
여하튼 이렇게 시간낭비를 하지 말고 별도의 파일에 로그를 기록하고 volumes 설정으로 테스트가 끝난 후 보는 것을 추천한다.
목표
95th percentile이 1000ms 이하가 목표이다.
locust에서 95th percentile은 응답 시간의 분포에서 상위 5%를 제외한 최대 응답시간을 의미한다.
굳이 1000ms로 한 이유는 우리나라 정서에는 1초를 넘기면 힘들다고 생각하기 때문이다.
테스트 1 - 루트 폴더만 존재하는 상황에서 조회, 생성, 이동 테스트
import logging
import threading
from locust import HttpUser, TaskSet, task, between, events
import random
import requests
# 전역 Lock 객체 생성
lock = threading.Lock()
# 전역 데이터 관리
FOLDER_IDS = []
USER_ID = None
FOLDER_NAMES = []
# 로거 설정
logger = logging.getLogger("locust_test")
logger.setLevel(logging.DEBUG)
formatter = logging.Formatter('%(asctime)s %(levelname)s: %(message)s')
# requests 라이브러리의 로깅 설정
logging.getLogger("requests").setLevel(logging.DEBUG)
class FolderTaskSet(TaskSet):
def on_start(self):
"""테스트 시작 전 사용자 및 루트 폴더 생성."""
global USER_ID
with lock:
if USER_ID is None:
self.initialize_folder_names()
self.create_user()
def log_error(self, action, response, exception):
"""에러 로깅 메서드."""
if exception is not None:
logger.error("Error during %s: Exception=%s", action, exception)
elif response is not None:
# 응답 본문(response.text)을 로깅
logger.error(
"Error during %s: Status=%s, ResponseBody=%s",
action,
response.status_code,
response.text if response.text is not None else "No response body"
)
else:
logger.error("No response or exception provided during %s", action)
def initialize_folder_names(self):
"""폴더 이름 리스트 초기화."""
global FOLDER_NAMES
FOLDER_NAMES = [f"folder_{i}" for i in range(1, 10001)]
def create_user(self):
"""사용자 생성 및 루트 폴더 등록."""
try:
response = self.client.post("/api/v1/users", json={"userName": "test_user"})
if response.status_code == 201:
id = response.json().get("id")
rootFolderId = response.json().get("rootFolderId")
global USER_ID
USER_ID = id
FOLDER_IDS.append(rootFolderId) # 루트 폴더를 전역 리스트에 추가
print(rootFolderId)
else:
self.log_error("create_user", response=response, exception=None)
except requests.exceptions.RequestException as e:
self.log_error("create_user", response=None, exception=e)
@task(6) # 폴더 조회: 6의 비율
def list_folders(self):
"""랜덤 폴더 조회 작업."""
global FOLDER_IDS
if FOLDER_IDS:
global USER_ID
folder_id = random.choice(FOLDER_IDS) # 폴더 리스트에서 랜덤 선택
try:
response = self.client.get(
f"/api/v1/folders/{folder_id}?userId={USER_ID}&cursorType=Folder&sortBy=createdAt&size=10&creatorId={USER_ID}",
timeout=20
)
if response.status_code != 200:
self.log_error("list_folders", response=response, exception=None)
except requests.exceptions.Timeout as e:
self.log_error("list_folders timeout", response=None, exception=e)
@task(2)
def create_folder(self):
"""랜덤 폴더를 기준으로 새로운 폴더 생성."""
global FOLDER_IDS
if FOLDER_IDS:
global USER_ID
global FOLDER_NAMES
parent_folder_id = random.choice(FOLDER_IDS) # 부모 폴더를 랜덤 선택
folder_name = random.choice(FOLDER_NAMES)
try:
response = self.client.post(
f"/api/v1/folders",
json={
"userId": USER_ID,
"parentFolderId": parent_folder_id,
"uploadFolderName": folder_name,
"creatorId": USER_ID
},
timeout=20
)
if response.status_code == 201:
id = response.json().get("id")
FOLDER_IDS.append(id)
else:
self.log_error("create_folder", response=response, exception=None)
except requests.exceptions.Timeout as e:
self.log_error("create_folder timeout", response=None, exception=e)
@task(2) # 폴더 이동: 2의 비율
def move_folder(self):
"""랜덤 폴더 이동 작업."""
global FOLDER_IDS
if len(FOLDER_IDS) > 100: # 최소 100개 이상의 폴더가 있어야 이동 가능
source_folder = random.choice(FOLDER_IDS)
target_folder = random.choice(FOLDER_IDS)
while source_folder == target_folder: # 소스와 대상이 같지 않도록 보장
target_folder = random.choice(FOLDER_IDS)
try:
response = self.client.patch(
f"/api/v1/folders/{source_folder}",
json={
"userId": USER_ID,
"targetFolderId": target_folder
},
timeout=20
)
if response.status_code != 200:
self.log_error("move_folder", response=response, exception=None)
except requests.exceptions.Timeout as e:
self.log_error("move_folder timeout", response=None, exception=e)
class FolderUser(HttpUser):
tasks = [FolderTaskSet]
wait_time = between(1, 3)
@events.request.add_listener
def log_request(request_type, name, response_time, response_length, exception, context, **kwargs):
if exception:
print(f"Request failed! Exception: {exception}")사용한 Locust 파일이다. 처음 사용자를 생성하여 사용자 id와 root 폴더의 id를 저장하고, 이를 기반으로 점차 폴더를 생성하고 조회하고 이동하는 코드이다. 폴더가 너무 적은 상황에서는 오히려 자식 폴더로 이동하는 문제가 많을 것 같아서 100개를 넘어서면 이동 작업을 실행할 수 있도록 했다. 그리고 locust의 경우 각 사용자 인스턴스마다 몇 초 후에 요청을 보낼지 설정할 수 있었는데, 그게 wait_time이다. 실제 사람이 서비스를 사용할 때도 응답받은 화면을 보고 잠깐의 시간이 지난 후에 다른 작업을 하기 때문에 해당 옵션을 사용하면 괜찮을 것 같았다. 한국인은 급하니까 1~3초 사이의 대기 시간을 가지고 요청을 보내도록 했다.

부하 테스트를 하다 보니 이런 알 수 없는 에러가 발생했는데, 서버에도 로그가 남지 않았다. status 값과 responseBody 값도 없는 것을 보아 HTTP 수준에서 처리하지 못하고 그 하위 계층에서 뭔가 예외가 터진 것으로 보인다. 정확한 이유는 모르겠지만 추측하기로는 부하가 너무 많아서 서버에 도달하기 전에 타임아웃이 발생했다던지, open 한 파일의 수에 제한이 걸려서 커넥션 연결을 못했다던지 그런 이유가 아닐까 싶다. 이걸 와이어샤크 같은 것으로 까보려고 해도 부하 테스트를 하면 패킷이 너무 많아서 할 수 없었다..
그래서 로커스트 코드에서 실패한 요청에 대해서 에러 로그를 남기도록 했고, 그게 log_request 함수이다.

어떤 에러인지 보니 원격 서버에서 요청을 끊는다고 한다. 아무리 생각해도 타임아웃 외에는 문제가 없을 것 같아서 요청에도 타임아웃을 걸어서 다시 테스트를 했다.

10초로 걸어보고 했더니 10초 뒤에 타임아웃이 발생했고, 정체를 알 수 없던 에러는 발생하지 않았다. 서버에 도달조차 못하고 대기하던 패킷들이 타임아웃이 발생해서 끊어진 것이 아닐까?라는 생각이다.
개선된 서버 사용자 150, 5분간 테스트




150명도 지금 간당간당한 것 같음. 그래서 200명으로 다시 해봤음.
개선된 서버 사용자 200, 5분간 테스트

순식간에 1000ms를 넘겨버렸다.
우선 위와 같이 대부분 1000ms로 응답이 오는 이유는 아마 락 대기 시간을 1000ms로 한 것이 가장 영향이 큰 것 같다. 무한으로 대기를 하지 않고 예외를 응답하니까.
참고로 컨테이너 상태를 docker stats로 봤는데, 해당 스크린샷은 가장 사용률이 높게 측정된 순간을 찍었다. cpu를 2개 사용해서 200%가 최대치인 것 같은데, 저런 순간을 제외하면 대부분 140~150%를 유지했다. 그리고 레디스의 경우 확실히 리소스 제한을 더 해도 상관없을 것 같다.
기존 서버 사용자 150, 5분간 테스트


생각보다 대부분 너무 평화롭다. 컨테이너 cpu사용량을 봐도 큰 문제가 없어 보인다. 추측하기로는 DB 수준에서 데드락이 발생하면 빠르게 예외를 발생시키고 트랜잭션 하나를 종료하기 때문인 것 같다. 그래서 실패율이 높은 대신, 실패 응답도 응답으로 치니 응답 시간 자체는 대체적으로 빠른 현상이 나타나는 것으로 보인다.
하지만 시간이 지나면서 폴더의 깊이가 어느 정도 깊어지고, 그런 폴더가 이동하는 작업을 수행할 때 굉장히 많은 폴더에 대해 락을 걸고 이동하기 때문에 위와 같이 응답 시간이 크게 지연되는 현상을 볼 수 있는 것 같다.
그리고 매 테스트마다 동일한 환경을 위해 테이블의 데이터를 지우는데, 확실히 실패율이 높으니 생성된 폴더의 수도 적었다.

이게 기존 서버의 삭제된 row 수인데, 아래는 개선된 서버의 삭제된 row 수이다.


이건 같은 조건으로 한 번 더 테스트를 한 결과인데, 1000ms 안으로 응답을 받을 수 있었다. 실패율은 높지만, 기존 목표인 1000ms 응답이 기존 서버도 문제가 없었다. 이전 결과와 너무 차이가 나서 생각을 해 보니, 폴더 트리가 어느 정도 크게 만들어지지 않는다면 생각보다 오래 걸리는 작업이 없을 수 있는 문제가 있었다. 결국 요청은 랜덤으로 하니까 이런 문제가 발생한 것 같아서 폴더 트리를 더 크게 만들고자 테스트 시간을 10분으로 설정하고 다시 비교를 진행했다.
기존 서버 사용자 150, 10분

이번에는 생각보다 빠르게 1000ms를 돌파했지만, 이전과는 다르게 그런 모습들이 자주 보인다. 이후 추가로 진행한 테스트도 결과는 비슷했다.
기존 서버 사용자 120, 10분


확실히 사용자가 줄어서 요청 수가 줄어드니 이전과는 다른 결과가 나타난다. 물론 목표인 1000ms는 넘겼지만 그 경우가 확실히 줄어들었다. 그래서 데이터가 얼마나 생성되었는지 확인을 해보니 약 6000개의 폴더가 생성된 것을 확인할 수 있었다. 충분히 큰 구조가 형성되면 위와 같이 지연되는 문제가 발생하는 것이다.
기존 서버 사용자 100, 10분

사용자를 더 줄였을 때도 마찬가지였다. 테스트 시간이 길어지니 5분 이후에도 1000ms가 넘는 그래프를 볼 수 있다.
기존 서버 사용자 90, 10분

사용자가 조금만 줄어도 생각보다 큰 차이를 보였다. 아마 운이 좋은 편인 것 같긴 하다. 그럼에도 실패율을 보면 4%나 된다. 사용자 수를 줄여도 4%면 꽤 큰 문제인 것 같다.
기존 서버들을 살펴보면 대부분 실패율이 상대적으로 높은 편이다. 그래서 파일에 기록한 로그를 살펴보니 아래와 같이 대부분 데드락 이슈가 발생했음을 알 수 있었다.

개선된 서버 사용자 150, 10분


개선된 서버는 5분이나 10분이나 큰 차이는 없는 것 같다. 다만 분산락을 사용할 때 동시에 하나의 요청만 처리하기로 했기 때문인지 전체적으로 95th percentile은 높게 측정이 되었다. 하지만 기존 서버와 다른 점은 실패율이 1~2%라는 점이다. 사용자를 늘리고 테스트 시간을 늘렸음에도 낮은 실패율을 보여준다. 기존 서버가 사용자 수가 늘고 테스트 시간이 늘어남에 따라 실패율이 높아졌던 것을 보면 현재 서버가 더 안정적으로 개선되었다고 생각한다.
개선 전 서버와 비교했을 때 전체적으로 동시 처리량은 늘었다고 생각한다. 왜냐하면 RPS 자체는 실패 응답도 RPS 계산에 포함되어서 서로 큰 차이가 없지만, 실패율을 보면 개선된 서버는 실패율 차이만큼 작업을 더 처리했기 때문이다.

여기서 두 번째 필드 값이 실패한 요청의 수인데 대략 1~2%로 보인다. 기존 서버는 150명 기준으로 약 8%의 실패율을 기록했으니 요청 수로 따지면 큰 차이가 난다.
아래는 사용자 200명 기준으로 진행한 테스트인데, 순식간에 실패율이 높아져서 개선된 서버는 150이 최대치인 것 같다.
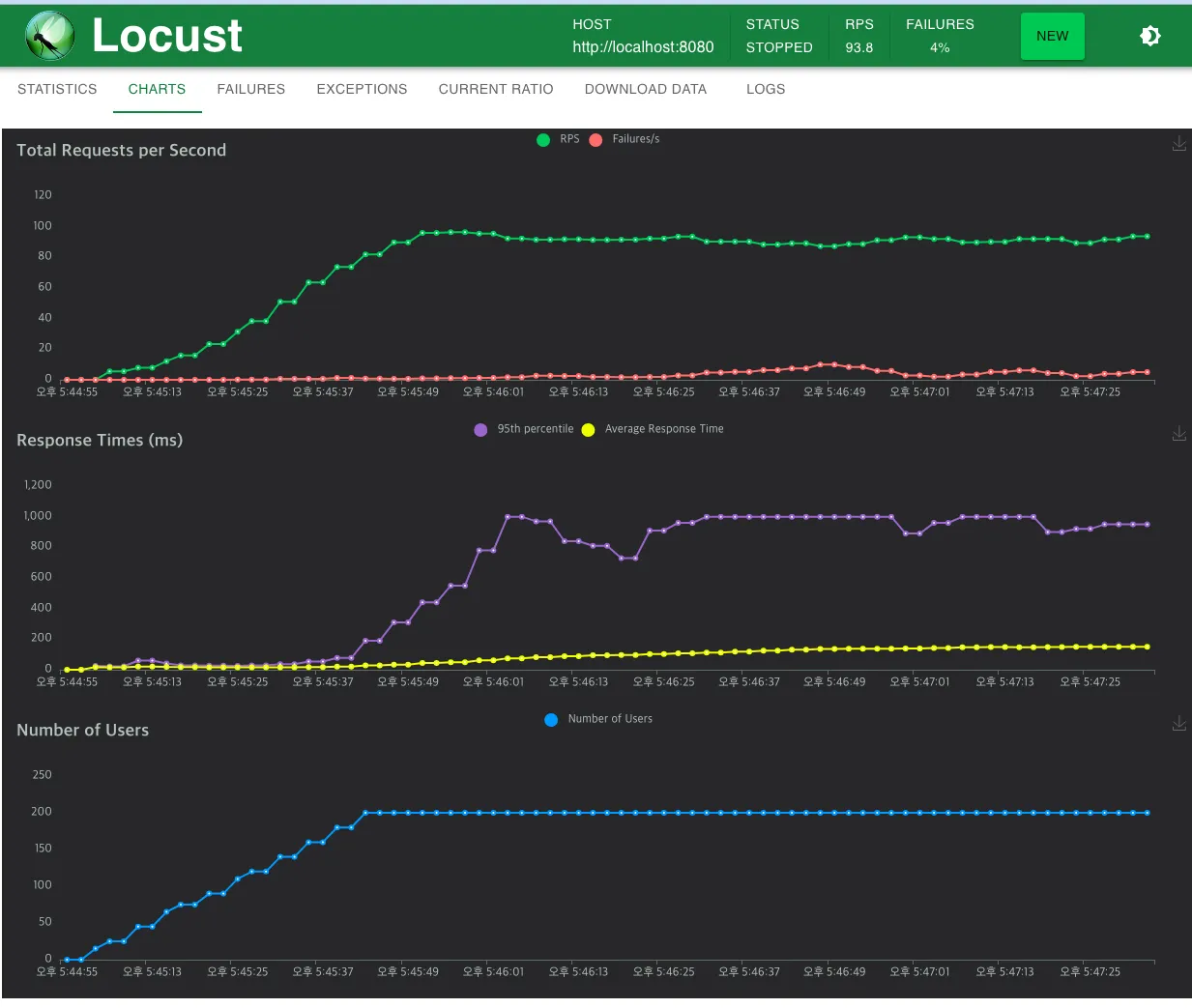
조회와 이동만 테스트
이 테스트는 락을 가장 많이 사용하는 이동에 대한 요청만 할 때 조회를 하면 성능 차이가 얼마나 나는지 궁금해서 진행했다.
그래서 이미 생성된 폴더 트리에서 테스트를 진행했고, 해당 폴더 트리는 이전 테스트를 진행하며 만들어진 폴더 트리로 진행했다.

대략 8000개의 폴더가 트리를 구성하고 있었다.
locust 파일
import logging
import threading
from locust import HttpUser, TaskSet, task, between, events
from collections import deque
import random
import requests
# 전역 데이터 관리
FOLDER_IDS = [194766]
USER_ID = 104
FOLDER_NAMES = []
# 로거 설정
logger = logging.getLogger("locust_test")
logger.setLevel(logging.DEBUG)
formatter = logging.Formatter('%(asctime)s %(levelname)s: %(message)s')
# requests 라이브러리의 로깅 설정
logging.getLogger("requests").setLevel(logging.DEBUG)
class FolderTaskSet(TaskSet):
def on_start(self):
"""테스트 시작 전 사용자 및 루트 폴더 생성."""
global FOLDER_IDS
FOLDER_IDS.extend(range(194767, 203110))
def log_error(self, action, response, exception):
"""에러 로깅 메서드."""
if exception is not None:
logger.error("Error during %s: Exception=%s", action, exception)
elif response is not None:
# 응답 본문(response.text)을 로깅
logger.error(
"Error during %s: Status=%s, ResponseBody=%s",
action,
response.status_code,
response.text if response.text is not None else "No response body"
)
else:
logger.error("No response or exception provided during %s", action)
@task(8)
def list_folders(self):
"""랜덤 폴더 조회 작업."""
global FOLDER_IDS
if FOLDER_IDS:
global USER_ID
folder_id = random.choice(FOLDER_IDS) # 폴더 리스트에서 랜덤 선택
try:
response = self.client.get(
f"/api/v1/folders/{folder_id}?userId={USER_ID}&cursorType=Folder&sortBy=createdAt&size=10&creatorId={USER_ID}",
timeout=20
)
if response.status_code != 200:
self.log_error("list_folders", response=response, exception=None)
except requests.exceptions.Timeout as e:
self.log_error("list_folders timeout", response=None, exception=e)
@task(2)
def move_folder(self):
"""랜덤 폴더 이동 작업."""
global FOLDER_IDS
if len(FOLDER_IDS) > 100: # 최소 100개 이상의 폴더가 있어야 이동 가능
source_folder = random.choice(FOLDER_IDS)
target_folder = random.choice(FOLDER_IDS)
while source_folder == target_folder: # 소스와 대상이 같지 않도록 보장
target_folder = random.choice(FOLDER_IDS)
try:
response = self.client.patch(
f"/api/v1/folders/{source_folder}",
json={
"userId": USER_ID,
"targetFolderId": target_folder
},
timeout=20
)
if response.status_code != 200:
self.log_error("move_folder", response=response, exception=None)
except requests.exceptions.Timeout as e:
self.log_error("move_folder timeout", response=None, exception=e)
class FolderUser(HttpUser):
tasks = [FolderTaskSet]
wait_time = between(1, 3)
@events.request.add_listener
def log_request(request_type, name, response_time, response_length, exception, context, **kwargs):
if exception:
print(f"Request failed! Exception: {exception}")조회와 이동의 비율은 8:2로 진행했다.
개선된 서버 사용자 150, 10분



아무것도 없는 상태에서 생성하고 조회하고 이동하는 테스트와는 다르게 실패율도 3%로 증가했고, 에러 로그를 보니 최대 폴더 깊이를 초과했다는 에러가 많았다. 이미 만들어진 폴더 트리를 사용하니 당연한 결과였다. 또한 깊이가 깊어진 만큼 작업 시간이 길어지게 되고, 그만큼 락을 오래 소유하게 되니 전체적으로 응답 시간이 많이 튄 것을 볼 수 있었다.
또한 이전과는 다르게 테스트를 시작한 지 얼마 지나지 않고 응답 시간이 지연되는 모습을 볼 수 있었다.
개선된 서버 사용자 100, 10분

사용자 수를 줄이니 이전과 비슷한 결과가 나왔다. 실패율도 1%이고, 응답 시간도 150명일 때와 비교해서 안정적으로 나타난 것 같다.
기존 서버 사용자 100, 10분

우선 응답 시간도 1000ms를 초과한 응답이 나왔고, 실패율도 4%나 된다. 전체적인 그래프 자체는 중간중간 엄청 튀는 것 빼고는 안정적인 것처럼 보인다. 이런 것을 보면 생각보다 데드락을 감지하고 예외를 던지는 기능이 우수한 것 같다.


개선된 서버와는 다르게 폴더 깊이 보다는 데드락 이슈로 Internal Server Error가 더 많이 발생한 모습이다.
실패율이나 내가 목표로 했던 95th percentile을 1000ms 안으로 끊는 것을 기준으로 봤을 때 많이 개선되었다고 생각한다. 특히 부하가 심할수록 실패율이 점점 높아지는 것이 아닌, 일정량을 유지하고 있으며, 언제 크게 지연될지 알 수 없는 기존 서버 보다 1000ms 안으로 응답이 오는 현재 서버가 더 안정적이고 효율적이라고 생각한다.
후기
나름대로 문제를 찾아서 개선하려고 시도했고, 예상한 대로 개선이 된 것 같아 다행이라고 생각한다. 운영체제에서 데드락에 대해 학습할 때는 현대 운영체제는 데드락을 굳이 감지하고 예방하지 않는다고 했다. 그래서 이전에는 굳이 데드락이 발생하지 않도록 신경을 쓸 필요를 못 느꼈던 것 같다. 하지만 이러한 테스트를 진행하고 나니 데드락이 서버에 미치는 영향이 생각보다 크다는 것을 알게 되었다.
그리고 이번 테스트를 통해 타임아웃이 굉장히 중요하다는 것을 깨달았다. 타임아웃을 설정하지 않으니 커넥션을 놓지 않게 되어 RPS는 떨어지고 Response Times는 상승하는 것을 볼 수 있었다.

평소에는 DB 설정에서 타임아웃 설정 같은 것은 신경도 안 썼는데 이번 기회로 신경을 좀 써야 할 필요를 느꼈다.
그리고 DB lock이 성능에 미치는 영향 또한 체감할 수 있었다. 일관성을 위해서는 무조건 써야 한다고 생각했는데, 분산락으로 별도의 락을 활용하면서 일관성도 지키고 성능까지 개선할 수 있었다.
이제 파일 처리 개선하러 가야지..