728x90
객체와 테이블 매핑
@Entity
JPA가 관리하는 객체를 Entity라고 한다. JPA를 사용해서 테이블과 매핑할 클래스는 @Entity 어노테이션을 필수로 달아줘야 한다. 파라미터가 없는 public 또는 protected생성자를 필수로 구현해야 하며 final 클래스, enum, interface, inner클래스에 사용할 수 없다. 그리고 DB에 저장할 필드에도 final을 사용할 수 없다.
- name 속성
- JPA에서 사용할 Entity의 이름을 지정한다. 기본값으로 클래스 이름을 그대로 사용한다.
- 같은 이름이 있는게 아니라면 가급적 기본값을 사용하도록 한다.
@Table
Entity와 매핑할 테이블을 지정한다.
- name 속성
- 매핑할 테이블 이름을 지정한다.
- 실제 쿼리도 name에 지정된 테이블로 나가며 Entity이름을 기본값으로 사용한다.
- catalog 속성
- DB catalog 매핑
- schema 속성
- DB schema 매핑
- uniqueConstraints(DDL) 속성
- DDL 생성 시에 유니크 제약 조건을 생성한다.
DB 스키마 자동 생성
JPA는 애플리케이션 실행 시점에 DDL을 자동 생성하게 할 수 있다. 미리 테이블을 만들지 않아도 되어서 객체 중심의 개발을 할 수 있는 장점이 있다. DB에 직접적으로 영향을 미칠 수 있기 때문에 실제 서비스를 운영할 때는 쓰면 안 되고 개발 단계에서 사용하면 유용하다.
jpa:
hibernate:
ddl-auto: update
- 위와 같이 application.yml파일의 jpa.hibernate.ddl-auto에 자동 생성과 관련된 옵션을 설정할 수 있으며 아래와 같은 옵션들이 있다.

- create : 시작 시에 drop을 먼저 실행하고 생성한다.
- create-drop : 마지막에 drop으로 모든 테이블을 제거한다.
- update : 새로운 컬럼을 추가했을 때 해당 내용만 반영한다. 기존 테이블에 새로운 컬럼을 추가하면 해당 컬럼에 대해서 alter를 수행한다. 주의할 점은 컬럼을 지웠을 때에는 아무 쿼리도 발생하지 않는다.
- validate : 테이블에 없는 컬럼을 클래스에 필드로 추가했을 경우 에러가 발생한다.
- none : 무의미한 값을 옵션에 넣는 것과 같으며 관례상 집어넣는 값이다.
주의 사항
주의할 사항으로는 운영 장비에는 절대 create, create-drop, update를 사용하면 안 되며 권장 사항은 아래와 같다.
- 개발 초기 단계 : create,update
- 테스트 서버 : update, validate
- 스테이징, 운영 서버 : validate, none
- 로컬을 제외한 개발등의 모든 서버는 직접 스크립트를 짜서 반영하는 것을 권장한다고 한다.
DDL 생성 기능
- 제약 조건 추가
@Column(nullable = false, length = 10)- 유니크 제약 조건 추가
@Column(nullable = false, length = 10)
- 위 조건들은 JPA 실행 자체에는 영향을 주지 않고 DB에 영향을 준다.
- JPA가 실행될 때 이 어노테이션을 보고 런타임 때 무언가가 바뀌진 않고 DDL 생성에만 관여한다.
필드와 컬럼 매핑

@Column

- insertable, updatable은 해당 컬럼이 수정됐을 때 DB에 insert를 할 것인지 update를 할 거인지를 결정한다. 즉 insert, update 쿼리가 발생할 때 해당 컬럼을 반영할 것인지를 의미한다. 이때 false를 주면 메모리 상에만 존재하게 된다.
- unique
- 잘 안 쓴다고 한다. 이유로는 아래와 같이 unique키가 랜덤 한 이름으로 나와서 가독성이 안 좋기 때문이다.
- 위에서 언급한 @Table의 uniqueConstrains옵션을 주면 이름으로 설정할 수 있어 이 방법을 더 많이 사용한다고 한다.

@Temporal

- 날짜 타입인 java.util.Date, java.util.Calendar를 매핑할 때 사용한다.
- LocalDate, LocalDateTime을 사용할 때는 생략이 가능하다.
@Enumerated

- 자바의 enum타입을 매핑할 때 사용한다. 기본값이 ORDINAL인데 이는 사용하면 안 된다. 요구 사항이 추가되어 맨 앞에 다른 Enum이 추가되면 새로운 값이 0이 되는 등의 문제가 많아서 사용하지 않는다.
@Lob
- DB blob과 clob 타입을 매핑한다. 지정할 수 있는 속성은 없으며 문자는 clob, 나머지는 blob으로 매핑된다.
- clob
- String, char[], java.sql.CLOB
- blob
- byte[], java.sql.BLOB
@Transient
- 필드 매핑을 하지 않을 때 사용한다.
- DB에 저장이나 조회가 되지 않는다.
- 주로 메모리 상에서만 임시로 어떤 값을 보관하고 싶을 때 사용한다.
기본 키 매핑
직접 기본키(PK)를 할당하면 @Id를, 자동으로 생성할 땐 여기에 @GeneratedValue를 추가하여 사용한다.
IDENTITY

- GenerationType.IDENTITY는 기본 키 생성을 DB에 위임하는 것으로 MySQL의 AUTO_INCREMENT와 똑같다. 주로 MySQL, PostgreSQL, SQL Server, DB2에서 사용한다.
- DB에 값을 INSERT 해야 PK를 알 수 있다.
- 하지만 영속성 컨텍스트에서 관리되려면 아래와 같이 1차 캐시의 Id값에 PK값이 필요하다.

- 그래서 JPA는 IDENTITY 전략에서만 persist()로 영속화하자마자 바로 insert쿼리를 DB로 날린다.
- 그래서 persist() 이후에 getId()를 호출하면 select 쿼리문 없이 Id값을 알 수 있다.
SEQUENCE

- DB에 시퀀스 오브젝트를 만들어서 이 값을 통해 세팅한다. Oracle, PostgreSQL, DB2, H2에서 사용한다.
- persist() 메소드를 호출할 때에는 무조건 PK가 존재해야 한다.
- JPA는 SEQUENCE전략일 경우 Id값을 DB에서 먼저 가져온다. 이와 동시에 다음 시퀀스 값으로 넘어간다. 그렇기 때문에 persist() 시점에 id를 조회할 수 있다. 하지만 insert쿼리가 아직 발생한 것은 아님을 주의해야 한다.
- 영속성 컨텍스트에 남아 있다가 commit()이 발생하면 insert 쿼리가 호출된다.
- IDENTITY는 무조건 insert 쿼리를 날려야 했지만 SEQUENCE는 시퀀스 값만 가져오는 차이가 있다.
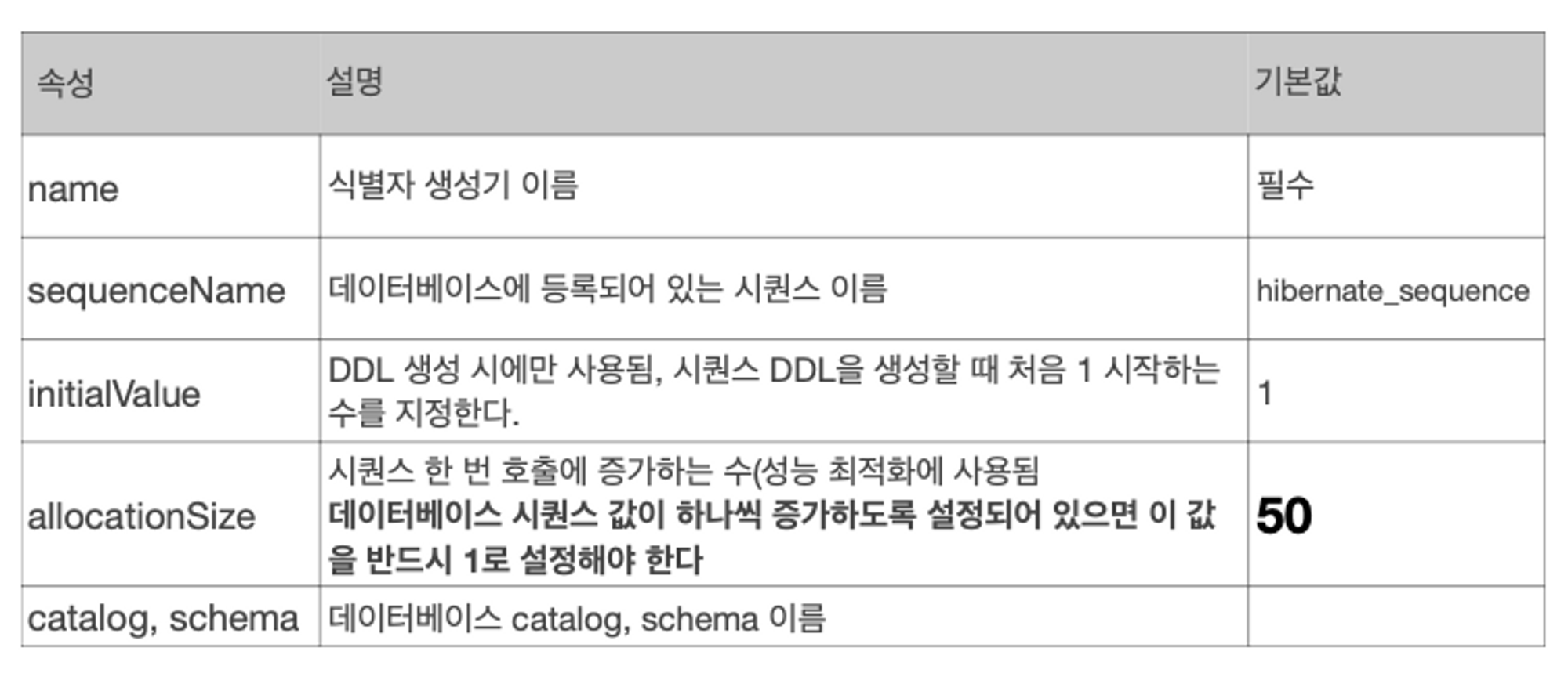
- 매번 시퀀스만 받기 위해 DB와 통신하는 것이 부담스러울 경우 allocationSize를 사용한다.
- allocationSize
- 기본값 50개를 DB에서 가져와서 메모리 상에 미리 준비해 놓고 거기서 사용한다. 기존과 다르게 계속 persist()하면서 다음 값을 가져오는 것이 아니다.
- 전부 사용하면 다음 50개를 가져오며 여러 웹 서버가 있어도 동시성 문제없이 다양한 이슈가 해결된다.
728x90
'Java > JPA' 카테고리의 다른 글
| [JPA] 즉시 로딩과 지연 로딩 (0) | 2023.06.25 |
|---|---|
| [JPA] 프록시 (0) | 2023.06.25 |
| [JPA] 다양한 연관 관계 매핑(다대일, 일대다, 일대일, 다대다) (0) | 2023.06.25 |
| [JPA] 연관 관계 (0) | 2023.06.24 |
| [JPA] 개념 정리(영속화, 영속성 컨텍스트) (0) | 2023.06.24 |