불변 객체(Immutable Object)
불변 객체란?
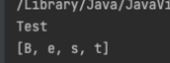
말 그대로 변하지 않는 객체로 객체 생성 이후 내부의 상태가 변하지 않는 객체를 의미한다. 불변 객체는 읽기만 가능하고 내부 상태를 제공하지 않거나 방어적 복사를 통해 제공한다. Java에서 대표적인 불변 객체로는 String이 있다. 불변 클래스이기 때문에 아래와 같이 char형 배열로 받아서 수정해도 바뀌지 않는다.
String test = "Test";
char[] testArray = test.toCharArray();
testArray[0] = 'B';
System.out.println(test);
System.out.println(Arrays.toString(testArray));
방어적 복사란?
흔히 주소 값을 복사하는 얕은 복사와 전부 다 새롭게 복사하는 깊은 복사는 다들 알 것이다. 얕은 복사는 주소 값을 복사하기 때문에 복사한 값을 수정하면 원본도 같이 바뀌고 깊은 복사는 아예 다른 주소값을 가지는 객체이기 때문에 서로에게 영향을 미치지 않는다.
방어적 복사는 간단하게 말하면 객체의 통만 바꿔 끼우는 것이다. List를 예로 들면 A가 있다고 가정할 때 이를 B에 방어적 복사를 사용하면 A와 B는 서로 다른 주소를 가지게 된다. 하지만 내부의 각 요소들의 주소는 공유되는 상태가 된다. 이 점이 깊은 복사와는 다르다.
List의 경우 B = new ArrayList<>(A);와 같이 방어적 복사를 한다. A와 B는 다른 주소를 가지지만 내부 요소들은 같은 주소를 가지기 때문에 A의 요소들을 변경하면 복사한 B의 요소도 함께 바뀐다. 하지만 A에 새로운 요소를 추가한다면 B에는 추가되지 않는다.
아래는 방어적 복사 예시이다. 방어적 복사를 했기 때문에 test2에 추가되는 객체는 test1에 적용되지 않으며 test1의 name과 test2의 name의 주소는 공유되고 있으므로 name객체의 값을 변경하면 test1과 test2에 모두 적용되는 모습을 볼 수 있다.
package algo_202304;
import java.io.*;
import java.util.*;
public class test {
public static void main(String[] args) {
ArrayList<Test> test1 = new ArrayList<>();
Test name = new Test("Kevin");
test1.add(name);
ArrayList<Test> test2 = new ArrayList<>(test1);
test2.add(new Test("Sally"));
System.out.println(test1);
System.out.println(test2);
System.out.println("///////");
name.setName("test");
System.out.println(test1);
System.out.println(test2);
}
public static class Test{
String name;
public Test(String name) {
this.name = name;
}
public void setName(String name){
this.name = name;
}
@Override
public String toString(){
return this.name;
}
}
}

여기까지 봤을 때 위의 String 예제에서도 값이 바뀌어야 하지 않나?라고 할 수 있지만 testArray[0] = ‘B’를 하는 순간 이 ‘B’가 new로 새로운 값이 들어오는 것과 같으므로 변경되지 않는다. 그래서 방어적 복사 예시에서 객체를 넣은 리스트를 이용해서 해당 객체의 내부를 조작하여 예시를 들은 것이다.
final을 사용해야 하는 이유
1. Thread-Safe 하여 병렬 프로그래밍에 유용하고 동기화를 고려하지 않아도 된다.
멀티 스레드 환경에서 동기화 문제가 발생하는 이유는 공유된 자원에 스레드가 동시에 접근하여 쓰기 때문이다. 하지만 공유 자원이 불변이라면 항상 동일한 값을 반환할 것이기 때문에 동기화를 고려하지 않아도 될 것이다. 이는 안정성을 높여주며 동기화를 하지 않아서 더 좋은 성능을 낼 수 있다.
2. 실패 원자적인(Failure Atomic) 메소드를 만들 수 있다.
가변 객체를 통해 개발을 하다가 예외가 발생하면 해당 객체가 불안정한 상태에 빠질 수 있고 이는 연쇄적으로 다른 에러를 발생시킬 수 있다. 하지만 불변 객체라면 항상 같은 값을 유지하기 때문에 메소드 호출 전의 상태를 유지할 수 있으며 예외가 발생하여도 오류가 발생하지 않은 것처럼 다음 로직을 처리할 수 있다.
3. Cache나 Map, Set 등의 요소로 활용하기에 더욱 적합하다.
Cache, Map , Set에 저장된 객체가 변경되었다면 이걸 갱신하는 작업이 필요하지만 불변 객체라면 한 번 저장된 이후에 다른 작업들을 고려하지 않아도 되기 때문에 사용하기 더 적합하다.
4. 부수 효과(Side Effect)를 피해 오류가능성을 최소화할 수 있다.
부수 효과란 변수의 값, 상태 등의 변화가 발생하는 효과를 의미한다.
만약 여러 객체들의 값을 변경한다면 객체의 상태를 예측하기 어려워질 것이다. 객체가 바뀐다면 바뀌게 한 메소드들을 살펴봐야 하고 결국 유지보수하기가 상당히 힘들어진다.
불변 객체를 사용한다면 기본적으로 값의 수정이 불가능하기 때문에 변경될 가능성이 낮고 그만큼 객체의 생성과 사용에 있어 상당히 제한이 걸린다. 그래서 메소드들은 자연스럽게 순수 함수로 구성될 것이고 다른 메소드가 호출되어도 객체의 상태가 유지되기 때문에 안전하게 객체를 사용할 수 있다. 이런 불변 객체의 사용이 오류를 줄여주고 유지보수성이 높은 코드를 작성하게 도와주는 것이다.
5. 다른 사람이 작성한 함수를 예측가능하며 안전하게 사용할 수 있다.
객체의 불변성은 협업 과정에서도 도움이 된다. 불변성이 보장된 함수라면 다른 사람이 개발한 함수를 걱정 없이 사용할 수 있다. 값이 바뀌지 않는다는 것을 보장받기 때문이다.
이전에 Entity와 DTO를 분리해야 하는 이유에 대해 정리한 내용이 있는데 Entity에 setter를 사용하지 않는 것처럼 해당 Entity를 조회한다면 항상 같은 형태로 나오는 것을 보장할 수 있으며 이는 조회에서 문제가 생겨도 Entity는 굳이 찾아보지 않아도 되는 장점이 될 것이다.
6. 가비지 컬렉션의 성능을 높일 수 있다.
불변 객체는 한번 생성 후 수정이 불가능한 객체로 Java에서는 final 키워드를 사용하여 생성할 수 있다.
이렇게 객체를 생성하기 위해서는 객체를 가지는 컨테이너도 존재할 것이다. 당연히 불변 객체가 먼저 생성되어야 컨테이너가 이 객체를 참조할 수 있을 것이다. 즉 불변 객체 생성 후 컨테이너가 해당 객체 참조를 할 것이고 이런 점이 가비지 컬렉션이 수행될 때 가비지 컬렉터가 컨테이너 하위의 불변 객체들은 검사하지 않도록 도와준다. 왜냐하면 컨테이너가 살아있다는 것은 하위의 불변 객체들 역시 처음 상태 그대로 참조되고 있을 것이기 때문이다.
결국 불변 객체를 활용하면 가비지 컬렉터가 스캔해야 하는 객체의 수가 줄어들기 때문에 메모리 영역과 빈도수 역시 줄어들 것이며 가비지 컬렉션이 수행되어도 지연되는 시간을 줄일 수 있을 것이다.
Java에서의 불변 객체 생성
final
Java에서는 불변성 확보를 위해 final 키워드를 제공한다. Java 변수들은 기본적으로 가변적인데 아래와 같이 final 키워드를 붙여 사용한다면 참조 값을 변경하지 못하도록 할 수 있다.
final String test = "Test";
test = "Best"; // -> 컴파일 에러 발생
위처럼 final이 붙은 변수의 값을 변경하면 컴파일 에러가 발생한다. 하지만 final도 문제가 있는데 내부의 객체 상태를 변경하는 것은 막지 못한다.
final ArrayList<String> list = new ArrayList<>();
list.add("test");
이렇게 final 키워드를 붙여서 ArrayList를 선언했지만 여기에 새로운 객체가 더해져도 문제가 발생하지 않는다. 그래서 Java에서는 참조에 의해 값이 변경될 수 있는 점들을 유의해야 하며 이를 방지하기 위해 불변 클래스로 만드는 방법이 있다.
불변 클래스
Java에서 불변 객체를 생성하기 위해서 아래와 같은 규칙에 따라 클래스를 생성해야 한다.
- 클래스를 final로 선언
- 모든 클래스 변수를 private과 final로 선언
- 객체를 생성하기 위한 생성자 또는 정적 팩토리 메소드 추가
- 참조로 변경가능성이 있는 경우 방어적 복사를 통해 전달
위의 규칙을 잘 따르기만 하면 되지만 나는 정적 팩토리 메소드가 무엇인지 몰라서 찾아보았다.
정적 팩토리 메소드란?(Static Factory Method)
팩토리라는 용어는 GoF 디자인 패턴 중 팩토리 패턴에서 유래했으며 객체를 생성하는 역할을 분리하겠다는 취지가 담겨있다. 즉 정적 팩토리 메소드란 객체 생성의 역할을 하는 클래스 메소드라는 의미로 생각해 볼 수 있다.
아래 예시는 내가 공통 응답을 만들며 구현한 팩토리 메소드이다.
//ErrorResponse.class
...
public static ErrorResponse of(HttpStatus httpStatus,int code, String message){
return ErrorResponse.builder()
.httpStatus(httpStatus)
.code(code)
.message(message)
.build();
}
...
위의 of 메소드처럼 new ErrorReponse를 하여 직접적으로 생성자를 통해 객체를 생성하는 것이 아닌 메소드를 통해서 객체를 생성하는 것을 정적 팩토리 메소드라고 한다.
다른 예시로 enum의 요소 조회 시에 사용하는 valueOf 메소드도 정적 팩토리 메소드의 일종이라고 할 수 있다. 미리 생성된 객체를 조회하는 메소드라 팩토리의 역할을 한다고는 볼 수 없지만 외부에서 원하는 객체를 반환해주기 때문에 결과적으로는 정적 팩토리 메소드라고 간주한다고 한다.
public enum Day{
MON,
TUE,
...
SUN;
}
Day monday = Day.valueOf("MON");
Day sunday = Day.valueOf("SUN");
이제 정적 팩토리 메소드가 뭔지 대충 알았다면 객체 생성은 생성자가 하는데 굳이 정적 팩토리 메소드를 따로 만들어서 객체 생성을 하는지 의문이 들 것이다. 나 또한 굳이 비효율적으로 한 번 더 거친다고?라는 생각을 했다.
생성자보다 더 좋은 점이 크게 4가지가 있었다.
정적 팩토리 메소드의 장점
1. 이름을 가질 수 있다.
객체는 생성 목적과 과정에 따라 다른 생성자를 사용하여 생성할 필요가 있다. 이는 객체의 내부 구조를 잘 알고 있어야 목적에 맞게 생성할 수 있을 것이다. 정적 팩토리 메소드를 사용한다면 메소드 이름에 객체의 생성 목적을 나타낼 수 있다.
public class TV{
private final String name;
private final int price;
private TV(String name, int price){
this.name = name;
this.price = price;
}
public static TV createTV(String name, int price){
return new TV(name,price);
}
public static TV createFreeTV(String name){
return new TV(name,0);
}
}
만약 정적 팩토리 메소드를 사용하지 않았다면 객체 생성 시에 new TV()를 사용하여 일반 TV인지 무료 TV인지 구분할 수 없었을 것이다. 이처럼 메소드만 보더라도 어떤 목적인지 알 수 있다.
2. 호출할 때마다 새로운 객체를 생성할 필요가 없다.
이 예시로는 enum이 대표적이다. 사용되는 값들의 개수가 정해져 있다면 해당 값을 미리 생성해 놓고 캐싱(조회)할 수 있는 구조로 만들 수 있는 장점이 있다.
public enum Day{
private final String day;
private Day(String day){
this.day = day;
}
private static final Map<String, Day> days = new HashMap<>();
static{
days.put("MON", new Day("Monday"));
days.put("TUE", new Day("Tuesday"));
...
days.put("SUN", new Day("Sunday"));
}
public static Day from(String day){
return days.get(day);
}
}
이제 사용 시 정적 팩토리 메소드만 호출해도 new를 사용할 필요가 없이 이미 생성된 객체에서 꺼내서 사용할 수 있다.
3. 하위 자료형 객체를 반환할 수 있다.
상속을 사용할 때 확인할 수 있는 장점이다. 생성자 역할을 하는 정적 팩토리 메소드가 반환값을 가지고 있기 때문에 가능하다.
public class OPIC{
...
private static OPIC of(int score){
if(score < 50){
return new IH();
}
if(score >= 50 && score <80){
return new IM();
}
if(score >= 80){
return new AL();
}
}
...
}
오픽 점수에 따라 등급을 매겨주는 방식이다. of()라는 정적 팩토리 메소드를 사용해서 객체 생성 시 점수에 따라 해당하는 등급 객체를 반환한다.
이와 같이 정적 팩토리 메소드를 사용하면 분기문을 통해 하위 타입의 객체를 반환할 수 있는 장점을 볼 수 있다.
4. 객체 생성을 캡슐화할 수 있다.
public class HumanDto{
private final String name;
private final int age;
private HumanDto(String name, int age){
this.name = name;
this.age = age;
}
public static HumanDto from(Human human){
return new HumanDto(human.getName(), human.getAge());
}
}
위와 같이 생성자를 private로 외부에서 사용하지 못하게 하고 정적 팩토리 메소드 from을 사용하면 외부에서 생성자의 내부 구현을 드러내지 않고 사용할 수 있다. 즉 캡슐화할 수 있다.
이처럼 정적 팩토리 메소드의 사용은 조금 더 가독성이 좋고 객체지향적으로 프로그래밍할 수 있도록 도와준다. 적절히 사용하면 얻을 수 있는 장점이 더 많아 보인다. 객체 간 형 변환이 필요하거나 여러 번의 객체 생성이 필요한 경우라면 생성자보다는 정적 팩토리 메소드를 사용하면 좋을 것 같다. 나도 다시 리팩토링을 해봐야겠다.
정적 팩토리 네이밍 컨벤션
- from : 하나의 매개 변수를 받아서 객체 생성을 할 때 사용한다.
- of : 여러 개의 매개 변수를 받아서 객체 생성을 할 때 사용한다.
- instance 또는 getInstance : 인스턴스를 생성하며 이전에 반환했던 것과 같을 수 있다.
- newInstance 또는 create : 새로운 인스턴스를 생성한다. 매번 새로운 인스턴스를 생성해서 반환한다.
'Java > Java' 카테고리의 다른 글
| Java 양방향 Socket 통신시 발생한 에러(socket is closed, 무한 readLine) (0) | 2023.12.05 |
|---|---|
| 자바 다시 학습 하면서 알게된 것(제네릭, Collection, Map) (0) | 2023.11.13 |
| try-with-resources를 사용하면 정말 close()가 호출될까? (0) | 2023.10.14 |
| [Java] 가비지 컬렉션(Garbage Collection)과 5가지 알고리즘 (0) | 2023.04.23 |
| Java 정리(JVM, 객체지향, 싱글톤 패턴) (0) | 2023.01.09 |